Melbourne – what a place to live! If you don’t like the weather, just wait a while and it will change. Positioned in the southeast of Australia, the most dramatic changes occur when summer north-westerly winds that channel over the country’s baking interior are replaced by south-westerlies coming roughly from Antarctica.

A typical headline in Melbourne after days of sweltering heat in summer.
These cool changes can be dramatic. Temperatures can drop from around 40 °C to 25 °C in a matter of an hour. That’s a drop of 25-30 °F for those working in Fahrenheit. Maximums can be more than 20 °C different from one day to the next. Cool changes often arrive in Melbourne after many days of sweltering heat; you can almost hear the city of 4 million sigh.
Predicting the timing of summer cool changes is important for various reasons regarding public safety, including bushfire management. The winds before and after a cool change are often strong, so bushfires can be extremely intense at this time. The worst fire events in Victoria are typically associated with these wind changes. Fires that might have spread along quite narrow fronts under north-westerlies can have massive fronts when the wind switches to the south west. The Kilmore East fire of 7 February 2009 (“Black Saturday”) is one example.
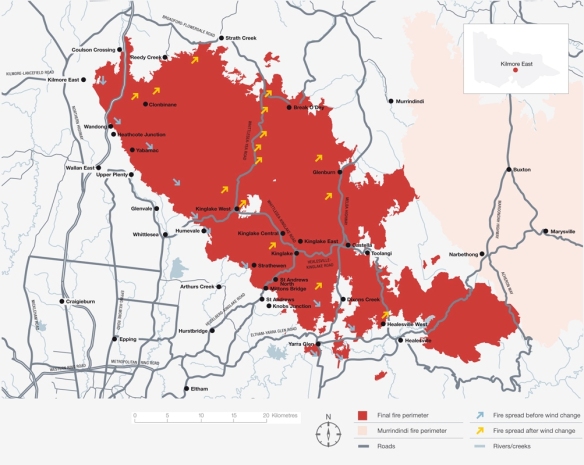
The effect of the windchange on the Kilmore East fore on Black Saturday from the Royal Commission’s report.
If you need to know when a change will occur, you should ask a weather forecaster. Weather systems in Melbourne typically move from west to east, and cold fronts that bring the change certainly match this pattern. While weather forecasters use models of atmospheric dynamics to predict the passage of these cold fronts, most of us don’t have access to the necessary computer power, data and expertise to solve the equations required to analyze these models.
So what should we do if we want to DIY? Thanks to the Australian Bureau of Meteorology (BoM), we can access data for a range of weather stations to the west of Melbourne. These weather stations record the wind direction and temperature, and the BoM displays these data every half hour via their website, and sometimes more frequently. So we can watch the cool change approach.
But can we do more? If we wanted to model the passage of a cold front to predict the timing of a wind change, how might we do that without the aid of numerical weather forecasting?
Let’s overlay a model of a cold front at Aireys Inlet on the map of weather stations. Cold fronts are usually aligned at an approximate 45 degree angle. Imagine it sweeping from west to east. What would be the simplest model for this cold front? Well, we might represent the cold front as a straight line and have it progressing at a constant speed to the east. Let’s assume the cold front is currently at Aireys Inlet (dark line), and we are interested in predicting where it will be at some time in the future (grey line).

Weather Stations to the west of Melbourne, and the modelled cold front moving from west (black) to east (grey).
This model has two parameters that we need to estimate. We need to know the slope of the cold front and its speed. Thinking of the model in this way helps us realise how it might be wrong – the cold front might not be a straight line (it might be curved), and it might not move at a constant velocity (it might change speed or direction). For example, a curved front slipping away to the south east might take longer to arrive than anticipated.
Bearing these simplifications in mind, we will plough on with our simple model, and leave more realistic ones to the experts. We can define the model geometrically. Think of the location of Aireys Inlet as being the origin of an x-y graph, so Aireys Inlet has coordinates (0, 0). Melbourne is approximately 76 km east of Aireys Inlet and 72 km north, so Melbourne has coordinates (76, 72). We can define the coordinates of all the other weather stations (and all other locations) in a similar way. A negative value for the x-value of the coordinate indicates that the site is to the west of Aireys Inlet and a negative y-value indicates the site is to the south of Aireys Inlet.
When the front is at Aireys Inlet, the equation defining its location is y = −bx (with b, a positive number, defining the backward slope of the front). If the front is moving eastward at a speed of v km/hour, then after t hours, the front will be vt kilometres to the east. So, the equation defining the location of the front at some other time is y = −b(x − vt).
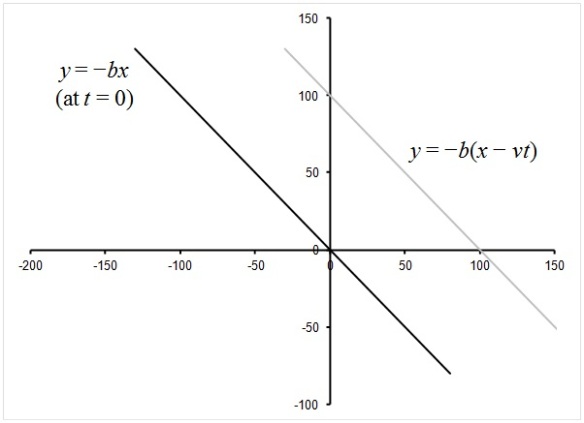
I’ve switched the model of the cold front onto an X-Y coordinate system. I’ve chosen the origin to be Airey’s Inlet, so all locations are measured relative to there.
The location and time in this equation is relative to a reference location; in this case I chose Aireys Inlet. So a negative value for time t indicates the passage of the front at a particular location prior to it arriving at Aireys Inlet.
We can manipulate the equation y = −b(x − vt) to determine the time of arrival of the front for any location x and y by solving for t. Thus:
x − vt = −y / b
−vt = −y / b − x
t = y / bv + x / v
This tells us that the time of arrival of the front at a particular location depends on the coordinates of the location (x, y), and the speed (v) and slope (b) of the front. So to determine the arrival time, we must estimate the two parameters b and v. If the front is at Aireys Inlet, then it will have passed at least some of the other weather stations, so we will know when it arrived at those locations. Therefore, we can fit the observed times and locations of the passage of the front to the equation t = y / bv + x / v to estimate b and v.
A simple way to estimate b and v is to construct the model as a linear regression. Manipulating the equation (by dividing both sides by x), we have:
t/x = y/xbv + 1/v,
in which the variable t/x is proportional to the variable y/x (with a constant of proportionality 1/bv) plus a constant 1/v.
This is simply a linear regression of the form Y = mX + c, based on the transformed variables Y = t/x and X = y/x. The speed and slope of the front are defined by the regression coefficients, and are v = 1/c and b = c/m.
Let’s apply that to some data on the passage of a cold front. Melbournians might remember the front that arrived on 17 January 2014 after a few days with maximums above 40°C. I’m sure tennis players in the Australian Open remember it – seeing Snoopy anyone?
Here are recorded times for the passage of the cold front at weather stations prior to them arriving at Aireys Inlet. The column t is the number of hours relative to arrival at Aireys Inlet. For example, the front arrived at Mount Gellibrand 15 minutes (0.25 hours) prior to its arrival at Aireys Inlet.
|
Location
|
x
|
y
|
Time
|
t
|
y/x
|
t/x
|
| Port Fairy |
−162.77
|
0.99
|
10:46
|
−2.77
|
−0.00611
|
0.01700
|
| Warrnambool |
−144.09
|
13.07
|
11:10
|
−2.37
|
−0.09072
|
0.01643
|
| Hamilton |
−182.00
|
82.39
|
11:48
|
−1.73
|
−0.45269
|
0.00952
|
| Cape Otway |
−48.93
|
−46.16
|
12:03
|
−1.48
|
0.94350
|
0.03032
|
| Mortlake |
−117.20
|
38.83
|
12:09
|
−1.38
|
−0.33131
|
0.01180
|
| Westmere |
−104.02
|
79.46
|
13:08
|
−0.40
|
−0.76391
|
0.00385
|
| Mount Gellibrand |
−27.07
|
24.66
|
13:17
|
−0.25
|
−0.91092
|
0.00924
|
| Aireys Inlet |
0.00
|
0.00
|
13:32
|
0.00
|
|
|
The linear regression of t/x versus y/x yields m = 0.0133 and c = 0.0171. Therefore, v = 58.5 km/hour and b = 1.28. The value of v means the front was estimated to be moving eastward at 58.5 km/hour, and the value of b implies it was approximately aligned at an angle of tan−1(1.28) = 52° above the horizontal (b = 1 would imply an angle of 45°).

The regression for the cool change on 17 January 2014. Note that the cool front took longer than predicted to reach both Geelong and Melbourne (blue dots; these were not used to construct the regression).
Using those parameters, the time at which the front is expected to arrive at a location with coordinates (x, y) is t = 0.0133y + 0.0171x (relative to the time it arrived at Airey’s Inlet). Different fronts will have different alignments and move at different speeds, so these parameters only apply to the passage of this particular front.
But let’s look at the regression relationship more closely; it has some interesting attributes. Firstly, the relationship is approximately linear, although clearly imperfect. The approximate linearity might encourage us to have some faith in our rather bold assumptions.
Also, one of the points, corresponding to Cape Otway, has a potentially large influence on the regression. Being to the right of the other data, it has “high leverage”; the regression line will tend to always pass quite close to that point.
Whether that high leverage is important will depend on where we wish to make predictions. It turns out that Melbourne is located very close to that point. Now, that might seem surprising at first because, compared to Cape Otway, Melbourne is in the opposite direction from Aireys Inlet. In fact, that is why Cape Otway and Melbourne have similar values for y/x (the “x-value” of the regression model) – the two locations are in opposite directions from Aireys Inlet.
This dependence of the regression on when the front reaches Cape Otway actually means we can very much simplify the model. We can use t/x for Cape Otway to predict t/x for Melbourne because they have very similar values of y/x. For Cape Otway, x = −48.93, and for Melbourne x = 76.14. If the front arrived at Cape Otway (relative to Aireys Inlet) at tCO, then the time it arrives at Melbourne, tM, is predicted from the expected dependence:
tCO / −48.93 = tM / 76.14.
Thus, tM = −tCO 76.14/48.93 = −1.56tCO.
That is, the time it takes for the front to arrive in Melbourne from Aireys Inlet is approximately the time it takes the front to travel between Cape Otway and Aireys Inlet multiplied by 1.56. The accuracy of this method can be assessed by comparing it to data on the passage of two fronts (17 Jan 2014 and 28 Jan 2014).
On 17 January, the front took 1.48 hours to travel between Cape Otway and Aireys Inlet, so our simplified model predicts the front’s arrival in Melbourne 2.3 hours after it passed through Aireys Inlet. The observed time was 3.2 hours, so the front took about 55 minutes longer than predicted. Thus, the data point for Melbourne is above that of Cape Otway.
On 28 January, the front took 1.56 hours to travel between Cape Otway and Aireys Inlet, so our simplified model predicts the front’s arrival in Melbourne 2.1 hours after it passed through Aireys Inlet. The observed time was 1.7 hours, so the front arrived about 25 minutes sooner than predicted. Thus, the data point for Melbourne is below that of Cape Otway.

The regression for the cool change on 28 January 2014. Note that the cool front arrived than predicted in both Geelong and Melbourne (blue dots; these were not used to construct the regression).
Interestingly, errors in the predictions could have been anticipated once the front arrived in Geelong. Because the front on 17 January took longer than predicted (by the regression) to arrive in Geelong, it seems to have travelled slower than anticipated. In contrast, the front on 28 January arrived in Geelong earlier than predicted, so its passage might have accelerated.
The simplification tM = −1.56tCO only works for predicting arrival of the front at Melbourne. If you want to predict the passage of the front at other locations, you might need to do the linear regression (or better still, ask a numerical weather forecaster).